Eigentlich wird über p-Werte und Signifikanztests schon seit ihrer „Erfindung“ Anfang des 20. Jahrhunderts sehr kontrovers diskutiert. Allerdings nicht so sehr über die Methodik selbst, sondern mehr über die (missbräuchliche) Verwendung und fragwürdige Interpretationen. Die haben dazu geführt, dass signifikante Ergebnisse etwa in klinischen Studien unglaublich gehypt werden und viele wichtige Fragen gar nicht mehr gestellt werden. Allerdings hat die Diskussion in den letzten Jahren wieder Fahrt aufgenommen, besonders im Zusammenhang mit der „Replikationskrise“. So hat 2015 das Journal “ Basic and Applied Social Psychology“ beschlossen, in Papern keine p-Werte zu veröffentlichen (was aber auch wiederum kritisiert wurde). Auch auf Twitter flammen entsprechende Diskussionen immer wieder auf und führen zu wahren „Kriegen“ zwischen Frequentisten und Bayesianer, während andere Stimmen daran erinnern, dass sich die wesentlichen Probleme mit keinem der beiden Ansätze wirklich lösen lassen.
Kurz zur Erinnerung: Wer Studien durchführt (egal ob im klinischen Kontext oder im Labor), muss immer mit zufälligen Effekten rechnen. Das liegt daran, dass die Studien in der Regel eine Stichprobe aus einer Grundgesamtheit darstellen und man aber eigentlich Aussagen über die Grundgesamtheit treffen will – in einer klinischen Studie sind das also etwa alle Patienten, die später mit dem betreffenden Arzneimittel behandelt werden sollen. Selbst wenn die Stichprobe repräsentativ ist und die Studie unter perfekten Bedingungen durchgeführt wurde, kann dennoch das Ergebnis der Stichprobe durch zufällige Effekte vom „wahren Wert“ in der Grundgesamtheit abweichen. Vergleicht man beispielsweise zwei Arzneimittel, muss man unterscheiden, ob eventuell gefundenen Unterschiede tatsächlich vorhanden sind oder nur zufällig entstanden sind.
An dieser Stelle werden dann häufig p-Werte mit Hilfe von Signifikanztests ermittelt. Das funktioniert so: Man formuliert zwei Hypothesen. Die Null-Hypothese besagt, dass der Unterschied zwischen den Arzneimitteln nur zufällig ist. Die Alternativ-Hypothese entsprechend, dass es einen „echten“ Unterschied gibt. Nun berechnet man anhand der Daten und des gewählten Signifikanzniveaus (meist 0,05) die Teststatistik und den p-Wert. Liegt der p-Wert unterhalb des gewählten Signifikanzniveaus, freuen sich alle, verwerfen die Nullhypothese und gehen davon aus, dass die Alternativhypothese zutrifft. Und schreiben natürlich etwas über signifikante Ergebnisse in ihr Paper.
Bevor man sich jedoch mitfreut und das neue Arzneimittel für besser hält, sollte man einige Aspekte bedenken.
1. Der p-Wert sagt nichts darüber aus, ob die Nullhypothese stimmt.
Zuerst einmal die besonders schlechte Nachricht: Der p-Wert ist definiert als die Wahrscheinlichkeit, die gemessenen oder noch extremere Daten zu erhalten, wenn die Nullhypothese stimmt. Anders ausgedrückt: Wie überraschend sind die Daten unter der Annahme der Nullhypothese? Wenn sie „sehr überraschend“ sind, kann es zwei Gründe dafür geben:
a) Die Nullhypothese stimmt, aber das Experiment hat ein extremes, wenn auch mögliches Ergebnis erzielt.
b) Die Nullhypothese stimmt nicht.
Welcher von den beiden Fällen zutrifft, lässt sich aber nicht mit Sicherheit sagen.
2. Ein p-Wert unter 0,05 heißt nicht, dass der Fehler beim Verwerfen der Nullhypothese (Typ-1-Fehler, alpha-Fehler) höchstens fünf Prozent beträgt.
Was wir eigentlich wissen wollen, wenn wir ein signifikantes Ergebnis sehen, ist: Wie groß ist die Wahrscheinlichkeit, dass doch die Nullhypothese stimmt, wenn dieses signifikante Ergebnis in der Studie auftritt? Oder anders gesagt: Wie wahrscheinlich ist ein falsch-positives Ergebnis? Das gesetzte Signifikanzniveau beschreibt das auf lange Sicht (wenn ich das Vorgehen auf 100 Studien anwende, komme ich bei fünf von ihnen zu einem falsch-positiven Ergebnis). Das sagt mir allerdings leider nichts über diese eine vorliegende Studie aus, die ich bewerten will. Denn die Wahrscheinlichkeit für ein falsch-positives Ergebnis hängt entscheidend auch von der Wahrscheinlichkeit meiner Null- bzw. Alternativhypothese sowie der Power der Studie ab (siehe auch 5.). Das lässt sich leicht nachvollziehen, wenn man einen Signifikanztest als diagnostischen Test betrachtet und entsprechend den positiven und negativen prädiktiven Wert berechnet.
3. Ein „signifikanter“ p-Wert von 0,05 ist eine willkürliche Grenze.
Der „Erfinder“ der p-Werte, der britische Statistiker Ronald Fisher, hatte den Wert 0,05 eher informell in einer Publikation gebraucht und eigentlich nicht als den Grenzwert postuliert, als der er heute vielfach angesehen ist. Die Wahrscheinlichkeit für diese oder extremere Daten unter der Nullhypothese (siehe 1.) ist ein Kontinuum und 0,05 bzw. 5 Prozent lediglich willkürlich gesetzt. Sie entspricht einem Effektschätzer, der mindestens zwei Standardfehler weit vom Effekt der Nullhypothese entfernt liegt.
4. Ob der p-Wert unter 0,05 liegt, hängt von vielen Annahmen über die Daten ab.
Je nachdem, welche Annahmen man über die Daten macht, können unterschiedliche p-Werte (und entsprechend signifikante oder nicht-signifikante Ergebnisse) resultieren. Dazu gehören etwa Annahmen über die Verteilung, aus der die Daten stammen, oder ob man ein- oder zweiseitige p-Werte berechnet. Macht man etwa keine Verteilungsannahmen und nutzt eine parameterfreie Methode, braucht man wesentlich extremere Werte, um zu einem signifikanten Ergebnis zu kommen, als wenn man etwa eine Normalverteilung unterstellt.
Ob der p-Wert signifikant wird, hängt von der Fallzahl ab.
Der p-Wert ist fallzahl-sensitiv. Bei stark streuenden Ergebnissen zwischen den einzelnen Teilnehmern kann der p-Wert nicht-signifikant ausfallen, obwohl tatsächlich ein Unterschied zwischen den Gruppen besteht. Aus diesem Grund ist eine sorgfältige Berechnung der Fallzahl notwendig, damit die Studie ausreichend Power hat, tatsächlich vorhandene Unterschiede auch tatsächlich zu erkennen. In diese Berechnung gehen unter anderem die vermutlichen Unterschiede zwischen den Gruppen sowie die interindividuelle Streuung ein.
Bei ausreichend häufigem Testen kann es viele falsch-positive signifikante Ergebnisse geben.
Dieses Phänomen ist auch als „Problem des multiplen Testens“ bekannt und manifestiert sich in klinischen Studien sowohl bei mehreren Endpunkten oder Behandlungen als auch in Subgruppenanalysen und Zwischenauswertungen. Wie schnell die falsch-positive Rate in die Höhe schießen kann, zeigt die Abbildung:
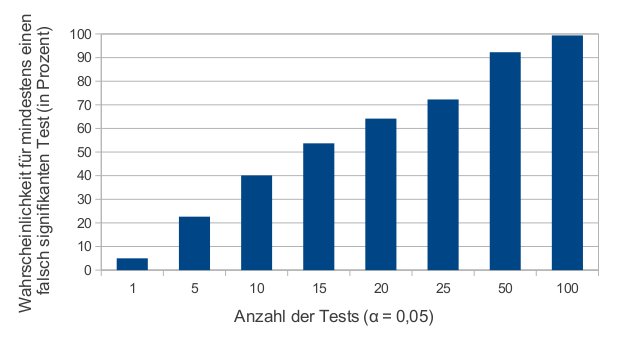{kind=link}

Findet man in einer Publikation eine ganze Batterie von p-Werten und wird das Problem im Methodenteil nicht adressiert, sollte man sehr genau hinschauen – vor allem dann, wenn nicht klar wird, ob tatsächlich alle Testergebnisse auch berichtet werden. Vorschläge zur Vermeidung dieses Problems umfassen etwa die Reduktion der getesteten Hypothesen und möglicherweise eine statistische Adjustierung für multiples Testen.
Statistisch signifikant heißt nicht klinisch relevant.
Wenn die Fallzahl nur ausreichend groß ist, wird jeder noch so kleine Unterschied zwischen den Behandlungsgruppen in einer Studie signifikant. Aber das heißt nicht automatisch, dass dieser Unterschied auch bedeutsam für den Patienten ist. Deshalb sollte man bei signifikanten Unterschieden auch jeweils genau hinschauen, wie groß dieser Unterschied tatsächlich ist. Für die Interpretation ist es wichtig, auch die Präzision des Effektschätzers zu bedenken – das wird durch das Konfidenzintervall ausgedrückt. Allerdings lauern auch bei der Interpretation von Konfidenzintervallen einige Fallstricke.
Zum Weiterlesen
Goodman S. A dirty dozen: Twelve p-value misconceptions. Semin Hematol 2008; 45; 135-140
Mark D et al. Understanding the role of p-values and hypothesis testing in clinical research. JAMA Cardiol 2016; 1:1048-1954
Greenland S et al. Statistical tests, p values, confidence intervals, and power: a guide to misinterpretations. Eur J Epidemiol 2016; 31:337-350
Ioannidis J. Why most published research findings are false. PLoS Med 2(8):e124
Colquoun D. An investigation of the false discovery rate and the misinterpretation of p-values. R Soc Open Sci 2014; 1:140216
Sterne J et al. Sifting the evidence – what’s wrong with significance tests? BMJ 2001; 322:226-31